Copias de Seguridad Reiterativas
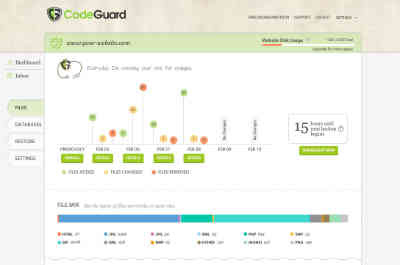
Después de la monitorización realizamos una copia de seguridad si detectamos cambios.
Visión General de la Copia de Seguridad
Si el proceso de monitorización detecta algún cambio en el código fuente de la web, los ficheros que se han cambiado o se han añadido se envian al repositorio de CodeGuard. Si se eliminan ficheros, también se envia al repositorio un registro de las eliminaciones. Los ficheros eliminados se eliminan del repositorio, los añadidos se añaden y los modificados son sobre-escritos para formar una nueva versión de la copia de seguridad, que se muestra en el panel de control.
Ya que los ficheros de las bases de datos se pueden disminuir a pequeños tamaños, CodeGuard transmite la base de datos completa, que se compara a la versión anterior. Si se encuentran cambios aparece una nueva versión en el panel de control.
Para saber que plan es el mejor para Ud,, precios, etc. Por favor, contáctenos.
Comparaciones de la Copia de Seguridad
| FUENTE FTP/SFTP | BASE DE DATOS MYSQL |
|
Después de realizar la primera copia de seguridad, las siguientes solo recogen los ficheros que se han marcado como cambiados durante el proceso de monitorización. Si no se detectan cambios, el proceso termina después de la monitorización. Este es más o menos el mismo proceso que la copia de seguridad inicial con algunas excepciones. Este proceso también incluye el proceso de monitorización que se ha detallado antes. Los pasos que difieren de la copia de seguridad inicial, se indican en cursiva:
|
Este proceso es similar a la de la copia de seguridad inicial, con la adición de estos dos pasos:
|